[aipingce]12月11日消息,继11月初零一万物发布Yi-34B 基座模型后,Yi-34B-Chat 微调模型在11月24日开源上线。开源两周,Yi-34B-Chat即获得全球开发者广泛关注,并在全球多个英文、中文大模型权威榜单名列前茅。 Yi模型开源首月,在Hugging Face社区下载量为16.8万,魔搭社区下载量1.2万。在GitHub 获得超过4900个Stars。 据介绍,截至目前,已有多家知名公司和机构推出了基于Yi模型基座的微调模型,比如猎豹旗下的猎户星空公司推出的OrionStar-Yi-34B-Chat模型,南方科技大学和粤港澳大湾区数字经济研究院(简称IDEA研究院)认知计算与自然语言研究中心(简称CCNL中心)联合发布的SUS-Chat-34B;AMD和Hugging Face合作的GPU加速大模型的实验中,也选择了Yi-6B作为范例项目。 零一万物宣布,邀请全球开发者共同测试使用 Yi-34B-Chat 模型能力,一起搭建 Yi 开源模型的应用生态系。 Yi-34B-Chat霸榜中英文大模型榜单 斯坦福大学研发的大语言模型评测 AlpacaEval Leaderboard 中,Yi-34B-Chat以94.08%的胜率,超越LLaMA2 Chat 70B、Claude 2、ChatGPT,成为世界范围内仅次于GPT-4 英语能力的大语言模型。 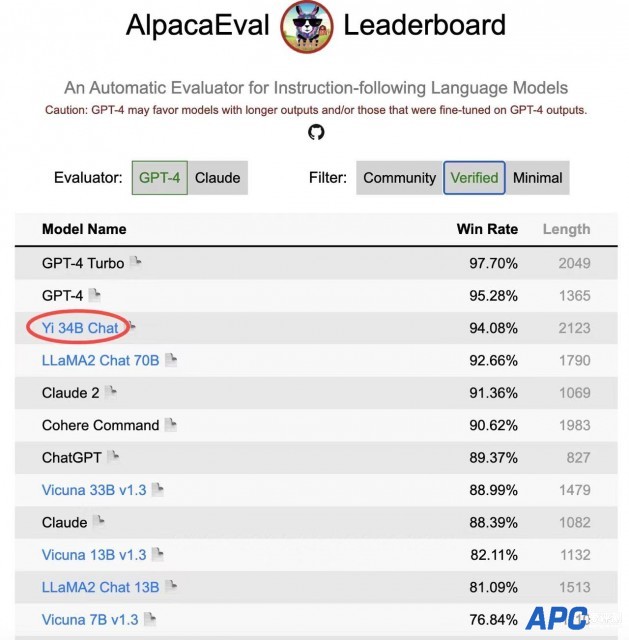 AlpacaEval Leaderboard排行榜(发布于2023年12月7日) 在加州大学伯克利分校主导的LMSYS ORG排行榜中,Yi-34B-Chat也以1102的Elo评分,晋升最新开源SOTA开源模型之列,性能表现追平GPT-3.5。伯克利LMSYS ORG排行榜采用了一个最为接近用户体感的 “聊天机器人竞技场” 特殊测评模式,让众多大语言模型在评测平台随机进行一对一 battle,通过众筹真实用户来进行线上实时盲测和匿名投票。 LMSYS ORG 在12月8日官宣的最新的榜单中,经25000的真实用户投票总数计算了20个大模型的总得分。在开源模型中,Yi-34B-Chat成为当之无愧的“最强王者” 之一(英语能力),榜单对评价:“Yi-34B-Chat 和 Tulu-2-DPO-70B 在开源界的进击表现已经追平 GPT-3.5”。 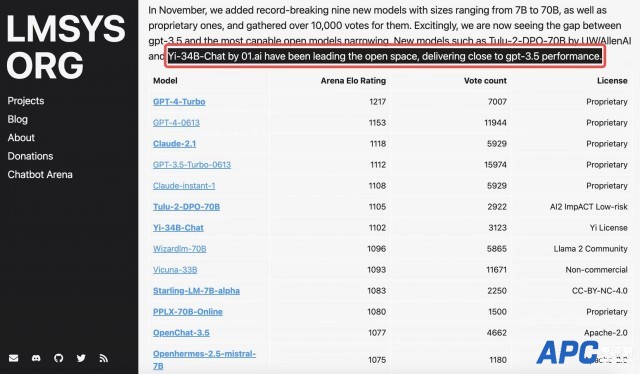 LMSYS ORG榜单(发布于2023年12月8日) 中文能力方面,Yi-34B-Chat 微调模型同样不遑多让。SuperCLUE是一项针对中文能力的排行榜,从基础能力、专业能力和中文特性能力三个不同的维度,评估模型的能力。根据11月底发布的《SuperCLUE中文大模型基准评测报告 2023》,11月下旬首度发布的 Yi-34B Chat,迅速晋升到和诸多国产优秀大模型齐平的 “卓越领导者” 象限,在多项基准评测中的 “SuperCLUE 大模型对战胜率” 这项关键指标上,Yi-34B-Chat 取得31.82%的胜率,仅次于GPT4-Turbo。 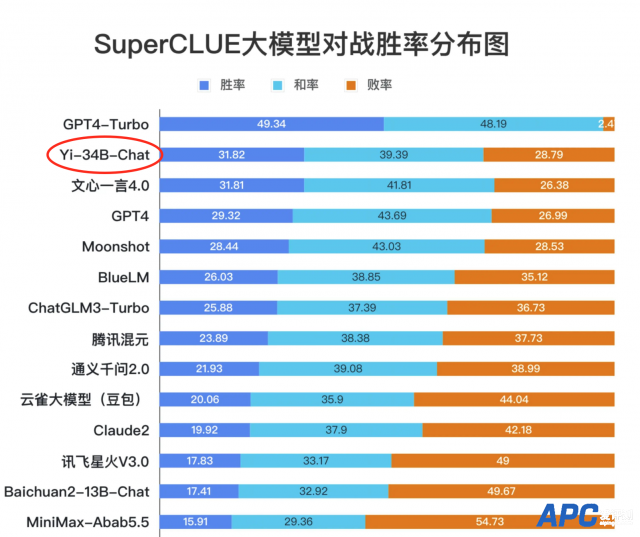 中文SuperCLUE排行榜(发布于2023年11月28日) 对广大开发社区来说特别值得一提的是,Yi-34B-Chat 微调模型还为开发者提供了 4bit/8bit 量化版模型。Yi-34B-Chat 4bit 量化版模型可以直接在消费级显卡(如RTX3090)上使用,训练成本友好。 实力源于Yi 强基座+创新对齐策略 今年11月6日,零一万物正式开源发布首款预训练大模型 Yi-34B。作为基座模型,Yi-34B能力表现突出,在Hugging Face Open LLM Leaderboard (pretrained) 大模型排行榜(2023年11月5日)、C-Eval中文权威榜单排行榜中Yi-34B均高居榜首;在MMLU、BBH等评测集上,Yi-34B在通用能力、知识推理、阅读理解等多项指标评比中全部胜出。 据零一万物介绍,除了 Yi 系列强基座的贡献以外,Yi-34B-Chat 模型的效果还得益于其人工智能对齐(AI Alignment)团队采用了一系列创新对齐策略。通过精心设计的指令微调流程,不仅强化了模型在理解和适应人类需求方面的能力,还使得模型与人类价值观对齐,包括帮助性(Helpful),可靠性(Honest),无害性(Harmless)等。 在强基座设定下,该团队采用了一种轻量化指令微调方案,该方案涵盖了单项能力提升和多项能力融合两个阶段。 其中,单项能力包括通用指令跟随、创意内容生成、数学、推理、编程、泛COT、对话交互等。通过大量的消融实验,针对模型单能力构建和多能力融合总结了独家认知经验。 在数据的量和质方面,一方面,团队在强基座模型上,实现仅需要少量数据(几条到几百条),就能激发模型特定单项能力;另一方面,数据质量比数量重要,少量高质量数据比大量低质量数据更好。通过关注超出模型能力的“低质量”数据,减少了模型“幻觉”。 在指令多样性与难度方面,团队通过在各能力项下构建任务体系,实现了训练数据中的指令均衡分布,大幅提升了模型泛化性。通过复合指令构造和指令难度进化,不仅提升了模型效果,也显著降低了对数据量的需求。 在风格一致性方面,团队发现训练数据的风格会影响模型收敛速度和能力上限的逼近程度,因此统一了回复风格,比如重点设计了CoT的回复风格,实现在轻量SFT情况下,避免了风格不一致加剧模型的“记忆”现象。 在多能力融合阶段,团队采用网格搜索的方法来决定数据配比和超参数的设置,通过基准测试和自建评测集的结果来指导搜索过程,成功实现模型的多能力融合。 “风波”过后 Eric Hartford已成Yi-34B的忠实拥趸 事实上,Yi-34B开源发布后,就获得了极大关注,甚至还闹出一场“风波”。 在11月初Yi-34B开源后,Hugging Face社区开发者Eric Hartford敏锐发现了模型存在的一个小问题。 于是,Eric Hartford在邮件中写道,“感谢你们提供了一个优秀的模型。Yi模型使用了与LLaMA模型完全相同的架构,只是将两个张量改了名字。由于围绕LLaMA架构有很多投资和工具,保持张量名称的一致性是有价值的。”Eric建议,在Yi被广泛传播前,及时恢复张量名称。 零一万物意识到命名问题的疏忽对开发者造成的不便,跟Eric和其他开发者提出说明,表达诚挚的歉意,并很快便在各开源平台重新提交模型及代码,完成了开源社区的版本更新。 然而Eric的这个建议,在国内被曲解、误读,进而引发了舆论关于Yi模型“抄袭”LLaMA的质疑。 事实上,一个模型核心技术护城河是在架构之上,通过数据训练获得的参数和代码。 零一万物团队在回应Yi模型“抄袭”LLaMA的质疑时就明确表示,在沿用了开源社区普遍使用的LLaMA 架构之上,零一万物团队从零开始,用高质量的数据集、自研训练科学和AI Infra打造了 Yi-34B 在内的系列模型。为了执行对比实验的需要,对部分推理参数进行了重新命名。原始出发点是为了充分测试模型,而非刻意隐瞒来源。 身处这场舆论风暴的中心,Eric自发且不遗余力为Yi辩护。 他在X(twitter)上写道:“他们没有在任何事情上撒谎。所有的模型都是在相互借鉴架构。架构是学术研究的产物,已经发表在论文中,任何人都可以自由使用,这丝毫不减损Yi团队的成就。他们从零开始使用自己创建的数据集训练Yi,对开源领域的贡献是值得赞扬的。”  现在,Eric已经成为Yi-34B的忠实拥趸,会使用Yi-34b-200k数据集训练其他的模型产品,并感叹丝滑般的训练体验。 另外,魔搭swift框架技术开发人员黄锦涛认为,因为沿用了Llama架构,Yi-34B的生态对开发者非常友好,部署方便轻盈,而且Llama生态中有很多加速技术工具,比如对推理加速的支持,均显著降低了成本。Yi还为开发者提供了4bit/8bit 量化版模型。Yi-34B-Chat 4bit 量化版模型可以直接在消费级显卡(如3090、4090)上使用,这就大大降低了基础模型运行的算力需求。对很多没有高效能显卡的个人开发者来说,显著降低了使用门槛。 Yi-34B-Chat中文理解能力演示 最后,看看Yi-34B-Chat 模型实力在不同的对话场景中实力如何,直接上几个直观的问题演示。 首先,来一段绕口令式的【中文理解】:小王给领导送了一份礼物后。领导说:“小王,你这是什么意思?”小王:“一点心意,意思意思。”领导:“你这就不够意思了。”小王:“小意思,小意思。”领导:“小王,你这人真有意思。”小王:“也没什么别的意思。”领导:“那我多不好意思。”小王:“是我不好意思。”这个意思到底是什么意思?  Yi-34B-Chat 给出了准确回复。 在看看Yi-34B-Chat生成文案的能力。“给我生成一个小红书文案,给大家安利一只豆沙色的口红。”  |








