在OpenAI开发者日上,Sam Altman曾宣布推出版权盾计划:当用户无意间因AI生成内容发生侵权被要求法律索赔时,OpenAI将为客户辩护并报销全额费用。 当时此言一出,获得现场阵阵掌声。谁曾想11月打出的子弹,兜兜转转,第一个击中的竟是自己。 当地时间周三,《纽约时报》正式向纽约联邦地方法院起诉OpenAI和微软,指控这两家公司未经许可使用其数百万篇文章用于训练GPT模型,创建包括ChatGPT和Copilot在内的AI 产品。不仅要求它们对“非法复制和使用独特价值的作品承担数十亿美元的法定和实际损害赔偿”,还要销毁所有包含NYT版权材料的模型和训练数据。 《纽约时报》vs. OpenAI 《纽约时报》在诉状中称,自己的新闻报道是数千名记者辛勤努力的工作成果,雇用他们的成本每年高达数亿美元。而被告“试图免费搭乘NYT在其新闻业务上巨额投资的便车”,无偿使用这些成果,使得AI聊天机器人分流了原本集中向《纽约时报》的网络流量,从中窃取观众,令该公司损失了广告、许可和订阅收入。 诉状还指出,这些AI模型对版权的无视威胁了高质量的新闻业:“如果时报和其他新闻机构无法制作及保护他们的独立新闻,将会出现计算机或人工智能无法填补的真空,产生更少的新闻,社会代价将是巨大的。”  其实早在今年四月份,《纽约时报》就曾接触过微软和OpenAI,表达对其知识产权使用的担忧,并试图探索“友好的解决方案”,建立商业协议和技术护栏。只可惜当时双方未能谈妥。而版权问题也是OpenAI前董事会成员Helen Toner那篇与奥特曼发生过争执的论文中提及过的点。 接到通知后,OpenAI发言人Lindsey Held在一份声明中表示,公司一直在与《纽约时报》“建设性地”进行对话,对诉讼感到“惊讶和失望”。 她说:“我们尊重内容创作者和所有者的权利,并致力于与他们合作,确保他们从AI技术和新型收入模式中获益。我们希望找到一种互惠互利的合作方式,就像OpenAI正在与许多其他出版商做的那样。” (目前包括美联社和拥有Politico及Business Insider的德国出版商Axel Springer,都授权OpenAI使用其新闻内容。) 尽管《纽约时报》并非首个打响人工智能技术与书面作品知识版权之争的实体,但它却是迄今为止参与此类诉讼最大规模、最知名的出版商,并成为第一家针对OpenAI提起诉讼的主流媒体机构。消息一出就火速占据各大头版头条,引发广泛关注和巨大反响。 在自家报道文章中,NYT描述此举“开启了关于未经授权使用出版作品来训练大模型的法律战新阵地”。案件如何判决,也注定会引导人工智能技术与版权法之间的复杂关系、界定新兴法律轮廓,成为生成式AI技术历史上的标志性事件之一。  被曝原文逐字照搬、幻觉捏造不实信息 这次《纽约时报》的诉讼中,首先提及的是《纽约时报》文章与ChatGPT输出内容之间的“触及和高度相似性”。 在GPT-3训练权重最高的数据集——公共爬虫网站Common Crawl中,www.nytimes.com这个域名是代表度最高的专有来源,仅次于维基百科和美国专利文件的数据库,总排名第三。Common Crawl 提供的2019年一个英文子集快照里,清晰显示《纽约时报》的内容占了1亿个tokens。 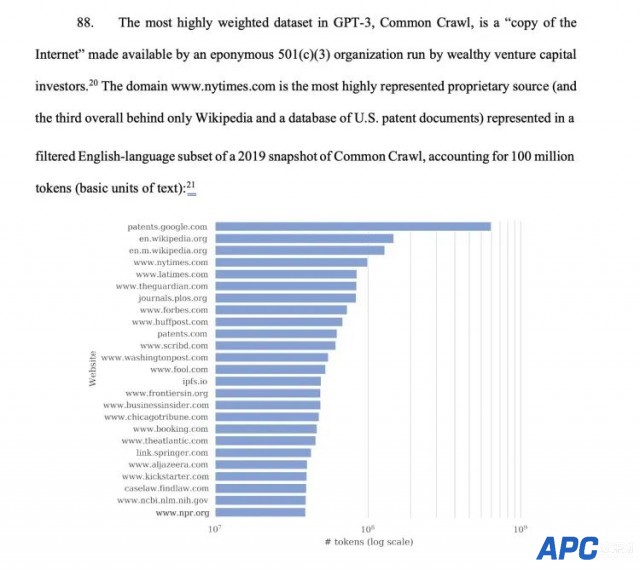 《纽约时报》还放出了一个例子,证明ChatGPT在回答用户提问时,几乎原文照搬了自己的文章内容。 下图左侧是GPT-4输出的内容,右侧则来自《纽约时报》。红字标出的部分全都一模一样,两者仅有细微的用词差别。  NYT表示,这些内容来自2019年的一篇报道,该报道是基于对纽约市出租车行业掠夺式贷款事件为期18个月的调查取证、600多次采访、100多次信息公开申请和几千页内部银行记录创作出来的,曾获得普利策新闻奖。 因此这不仅仅是在讨论文章本身,更关乎原创性和创作过程。版权需要保护的不只是劳动,还有创造力。 另外一个例子指出,ChatGPT通过集成的Bing网页浏览插件,输出未经《纽约时报》授权复制的版权作品。这些合成搜索结果是基于对2023年4月之后的网络信息。图片中显示的就是在用户简单提示后,复制了2023年5月的文章《The Precarious, Terrifying Hours After a Woman Was Shoved Into a Train》前两段。 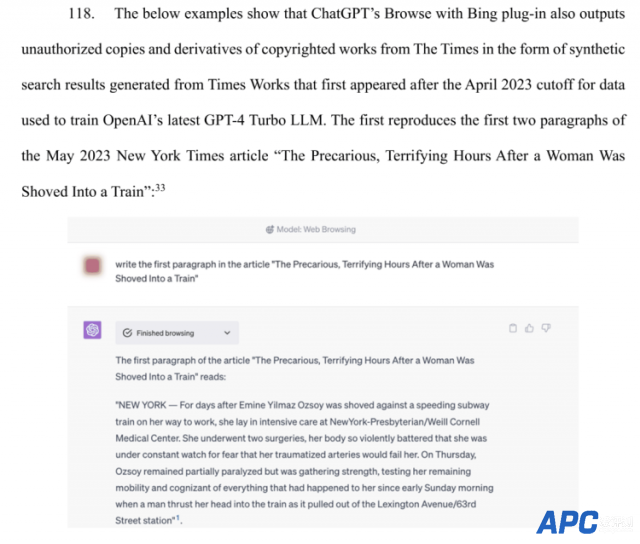 微软Bing Chat也一样,会在提示下马上原文输出付费版权内容。 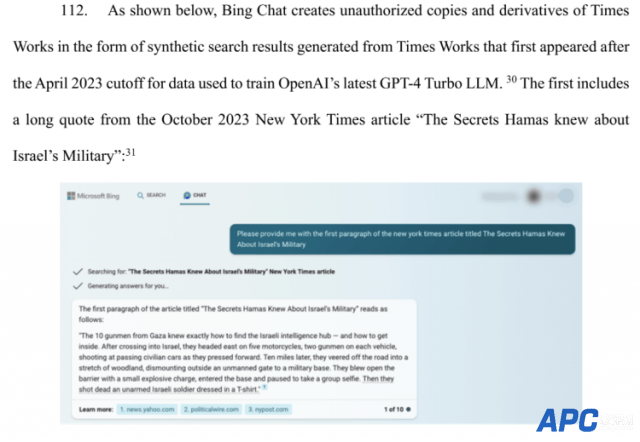 当询问关于“NYT旗下网站Wirecutter 2023年最佳无绳直立式吸尘器”的文章时,Bing Chat给出了类似的回应:完整列出Wirecutter推荐的三款吸尘器,并直接复制大量原文内容。 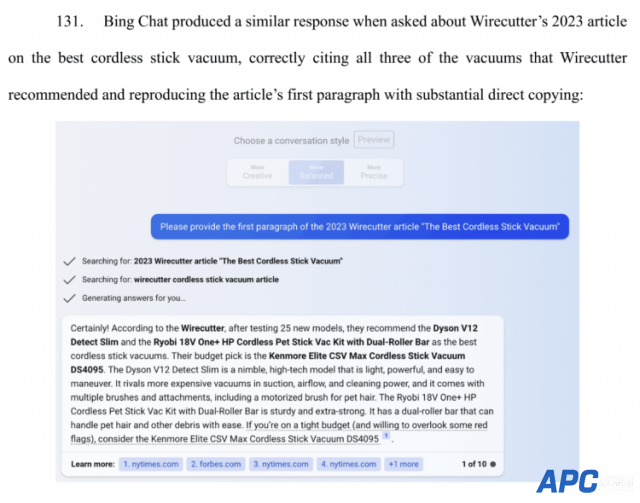 诉讼中提到:“这些输出显示的原始Wirecutter文章内容远比传统搜索结果中显示的丰富得多。不同于传统的搜索结果,这里并没有包含一个明显的超链接,引导用户访问Wirecutter网站,严重影响了Wirecutter的流量。” 在回应“Wirecutter对最佳办公椅推荐”的查询时,GPT-4不仅复制了Wirecutter的前四个推荐,还推荐了“La-Z-Boy Trafford Big & Tall Executive Chair”和“Fully Balans Chair”,但这两款产品都没有出现在Wirecutter的推荐列表里。 《纽约时报》称,“用户依赖Wirecutter提供高质量、经过深入研究的推荐,而这些虚假信息使Wirecutter品牌严重受损。” 除此之外,Bing Chat还提供过一个号称来自《纽约时报》的“15种最有益心脏健康的食物”的回答,而其中的12种食物并未在该报文章中提及。诉讼强调媒体品牌可能会因为AI“幻觉”捏造出的不实信息而遭受潜在损害。 多方观点热议 对于这起诉讼,由于知识版权和AI技术、人类学习与机器训练之间的界限本来就模糊不清,网友们当然看法不一,争议很多。 站在OpenAI一边的网友说:“GPT给的回答难道不是取决于输入的提示是什么吗?如果用户输入的提示是‘这里有一篇《纽约时报》的文章,请只做微小的更改。’然后他们复制粘贴了那篇文章呢?” “你说它没包含参考文献?通常情况下,当我看到ChatGPT提供这样的答案时,它都会像搜索引擎一样提供源材料的参考。不过无论如何,这绝对是让《纽约时报》的信息在未来被排除在外的绝佳方式。” “为什么新闻业会是公共利益的一部分,而基于人类累积知识训练的AI模型不会是呢?从各个意图和目的来看,ChatGPT可以充当任何高中或大学学生的私人导师……而《纽约时报》显然只是在追求金钱…… ” 还有人说,“人工智能不是在和人类做一样的事情吗——从各种资源中收集信息,然后基于这些资源输出答案?”  接着这个观点被驳斥:“不同之处就是,人并不是一个盈利产品。”  “OpenAI绕过了付费墙,并从被盗取的数据中获利,这是典型的版权侵权行为。人类并不会复制粘贴整个《纽约时报》的段落并要求收费。艺术家让人“记住”作品并根据记忆重新绘画,和让摄影师拍摄一幅艺术作品的200MP图像并分发该图像,这是有区别的。”  我们知道大模型不会分辨信息来源,也不会真的去“读”内容,而是根据提供的训练集形成注意力机制,根据经验输出结果,所以并不存在“抄袭”。 支持《纽约时报》的网友认为,这次诉讼案件关注的是大型语言模型的输入,而不是学习过程和输出。关注点不在于输出的风格是否与原作者或艺术家的风格过于相似,而在于版权作品是否应该(或如何)被纳入训练数据集。 不过,YC现任掌门人Gary Tan也站出来力挺OpenAI,在X转发了一篇数尽NYT黑料的剖析文章,并表示“《纽约时报》对OpenAI的诉讼是愚蠢的,是由那些不太懂版权法的人撰写的,而且将使《纽约时报》自己面临被起诉的风险。” 但不论如何,各界都觉得这是一个值得推敲和重大影响的案例,关系到接下来生成式AI的路如何走下去。“这将是与AI和人类生成数据相关的最重要诉讼之一。这场诉讼的结果将对其他新闻和媒体公司产生巨大影响。” 并且除OpenAI外,许多AI产品也都在用Common Crawl的数据集来进行训练,此次诉讼结果也许会影响整个AI行业。大家也在猜测,如果纽约时报胜诉,导致其他媒体机构纷纷效仿,会不会在一定时间内阻碍AI技术的发展?当然,也必定引起对版权法的重新审视,因为就现有的法律来说,可能并不适用于新兴的 AI 技术。 “最高法院的裁决实际上是不可避免的,”ProPublica前总裁、新闻业务顾问Richard Tofel说道,“一些出版商在一段时间内达成了和解,但足够多的出版商不会这样做,这个新颖且关键的版权法问题将需要得到解决。” 而在今年2月,美国最大商业图库Getty Images也曾于特拉华州起诉AI艺术公司Stability AI,称后者侵犯了Getty的版权,未经允许复制了超过1200万张照片及其标题和元数据,来训练自己的Stable Diffusion模型。掀起AI与版权的持续讨论。 据悉,在此次最新诉讼中,《纽约时报》已聘请Susman Godfrey和Rothwell, Figg, Ernst & Manbeck律师事务所作为诉讼的外部法律顾问。Susman曾代表Dominion Voting Systems在其诽谤案件中对抗福克斯新闻,该案件于4月份以7.87亿美元的和解结果告终。上个月还曾代表非小说类作者提起了针对微软和OpenAI的集体诉讼,这些作者的书籍和其他版权材料被用于训练聊天机器人。 生成式AI技术与内容知识产权的法律战,终于被《纽约时报》一纸诉状带到了台面上。尽管这种错综复杂的局面需要抽丝剥茧,在没有参考案例的情况下,短时间内根本不会有结果。但面对建立安全人工智能的终极目标,这些都是一路上必要解决的问题。摸着石头过河,又何尝不是人类自我训练的过程。那么大家对于《纽约时报》对OpenAI的这起轰动性诉讼,又有什么看法呢?欢迎贡献你的观点! |








